
De FHIR standaard beschrijft dat alle FHIR resources een tekstuele samenvatting zouden moeten bevatten. Wat is de bedoeling van die tekst? Hoe zou je die tekst moeten vullen?
Als je de resources in FHIR projecten bekijkt dan is daar meestal geen tekst in aanwezig. Volgens de FHIR standaard zouden (SHOULD) alle resources altijd een tekstuele samenvatting moeten bevatten om menselijke leesbaarheid van FHIR resources te kunnen garanderen. Grahame Grieve, de oorspronkelijke bedenker van FHIR, had zelfs liever gezien dat tekst verplicht (SHALL) zou zijn (zie zijn video hierover).
Als je de resources in FHIR projecten bekijkt dan is daar meestal geen tekst in aanwezig. Volgens de FHIR standaard zouden (SHOULD) alle resources altijd een tekstuele samenvatting moeten bevatten om menselijke leesbaarheid van FHIR resources te kunnen garanderen. Grahame Grieve, de oorspronkelijke bedenker van FHIR, had zelfs liever gezien dat tekst verplicht (SHALL) zou zijn (zie zijn video hierover).
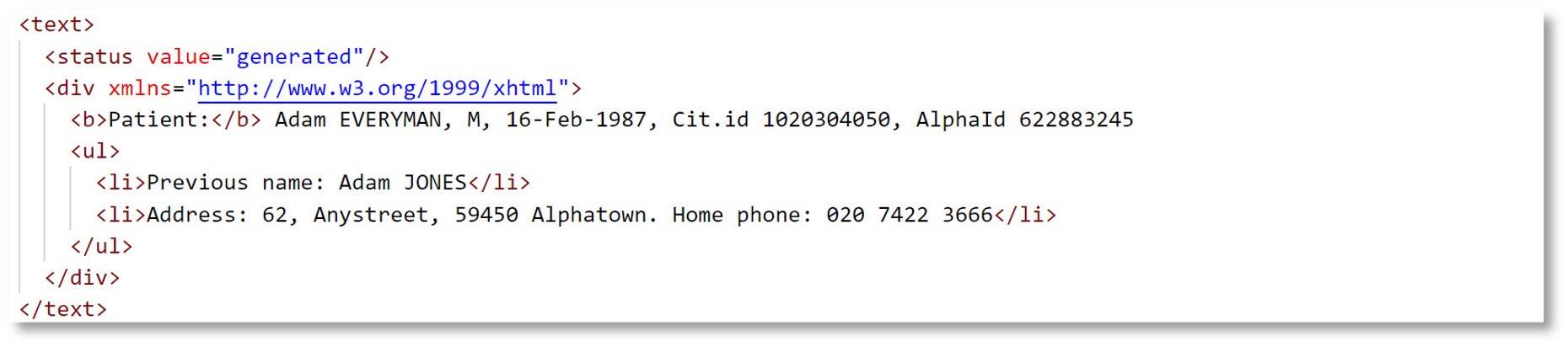
De tekst (Resource.text) is met name een terugvalmechanisme voor het geval een ontvanger de gestructureerde gegevens van een resource niet kan verwerken: in dat geval kan het de tekst tonen aan een menselijke lezer. Denk bijvoorbeeld aan een simpele app die slechts een paar resource types ondersteunt omdat het bedoeld is voor het monitoren van bepaalde bloedwaarden. Als deze app een zeer specialistisch resourcetype moet verwerken, bijvoorbeeld MolecularSequence, dan zal die app daar niets mee kunnen – maar het kan wel de tekst tonen aan een menselijke gebruiker van de app en daarmee alsnog interoperabiliteit bereiken.
Het gebruik van deze terugvalmogelijkheid naar een tekstvorm is een les die geleerd is uit de vele implementaties van de HL7 Clinical Document Architecture (CDA) standaard. De populariteit van die standaard was mede het resultaat van deze tekstuele mogelijkheid. FHIR heeft het gebruik van tekst bewust niet beperkt tot FHIR Documenten, maar legt een verplichting op aan REST, Documenten- en Message gebaseerde uitwisselingen van resources.
Verplichting tot het gebruik van tekst
Zolang je je in een beperkte context bevindt, zoals MedMij, waarin iedereen precies dezelfde set resources ondersteunt, afkomstig uit één FHIR release, en dezelfde set FHIR profielen, dan heeft tekst niet veel meerwaarde. Om die reden zie je dan ook dat softwareleveranciers die werken in zo’n beperkte context er voor kiezen het tekst gedeelte van de gebruikte FHIR resources niet te vullen, mede omdat tekst strikt genomen ook niet verplicht is (SHOULD).
Het verleden heeft laten zien dat zorggegevens die allereerst in een beperkte context wordt uitgewisseld op een later moment in een bredere context wordt (her)gebruikt. Je kunt er dan niet meer van uitgaan dat systemen alle data-elementen begrijpen die in een resource aanwezig zijn. Systemen ondersteunen de gebruikte FHIR-profielen niet, ondersteunen een andere (latere) versie van FHIR, kennen de gebruikte extensies niet, of verwerken de resources pas jaren nadat deze zijn aangemaakt. In het algemeen geldt: hoe verder je afstaat van de oorspronkelijke context van de resource, hoe moeilijker het wordt de daarin opgenomen gestructureerde data juist te interpreteren, hoe minder vertrouwen je zal hebben in de kwaliteit van de aangeboden data en hoe groter de noodzaak tot het aanwezig zijn van een tekstuele samenvatting.
Een MedMij-compatible PGO zal de eerdere genoemde MolecularSequence resource niet kunnen verwerken aangezien die resource niet tot de scope van MedMij behoort. Dit geldt eveneens voor alle resource typen en alle profielen die niet tot het MedMij afsprakenstelsel behoren. PGO's zullen zeker proberen veelgebruikte resource typen die officieel niet tot MedMij behoren toch enigermate te ondersteunen, maar zelfs dan zullen zij veelal terug moeten vallen op de tekst, aanwezig in resources.
Op korte termijn zien zorgorganisaties en softwareleveranciers op tegen de kosten van het ontwikkelen van software die het tekstgedeelte van resources moet vullen, iets wat vanwege de huidige beperkte context van FHIR projecten begrijpelijk is. Dit staat echter op gespannen voet met de lange termijn verwachting dat resources buiten hun oorspronkelijke context gebruikt gaan worden: dan is tekst wel nodig.
Inhoud van de tekst
Als tekst in een resource aanwezig is, dan dient die tekst de wezenlijke inhoud van de resource samen te vatten. Het moet mogelijk zijn uitsluitend de tekstuele versie van een FHIR resource aan een zorgverlener te tonen die op basis daarvan kan handelen. De FHIR standaard zegt niets over wat een ‘goede’ samenvatting (Engels: clinically safe summary) zou moeten zijn. Profielen en implementatiegidsen zouden daar overigens wel eisen aan kunnen stellen.
Nictiz heeft een generieke aanbeveling geschreven wat er in de tekst zou moeten worden opgenomen, waarbij ze zich baseren op de 5W's:
- Wat: resource type, status de activiteit die in resource beschreven is, type aanduiding van de activiteit (Waar ben je allergisch voor? Welke procedure hebben we het over?).
- Wie: de patiënt, de auteur, andere primaire actoren betrokken bij de activiteit beschreven in de resource
- Wanneer: zijn dit gegevens uit het verleden, of gaat het over toekomstige activiteiten?
- Waarom: wat ging hieraan vooraf, bijvoorbeeld een probleem of een verwijzing.
- Waar: plaats waar de vastgelegde activiteit plaats vond, plaatsvindt, of zal vinden.
- Context: overige contextuele informatie over de activiteit, zoals opnamegegevens, diagnosen, condities.
Je wilt zeker niet alle details van alle data-elementen meenemen in de tekst, naast bovengenoemde 5W's zou je ook kunnen kijken naar die data-elementen die verplicht zijn in een resource definitie, of die een kenmerk hebben dat aangeeft dat ze van bijzonder belang zijn, bijvoorbeeld data-elementen die een ‘sigma-label’ hebben, of die ‘must support’ of ‘is modifier’ zijn verklaard in een profiel. Data-elementen die uitsluitend bedoeld zijn voor de software verwerkbaarheid, zoals canonical URL's en logical Ids zouden nooit in de tekst moeten worden
opgenomen.
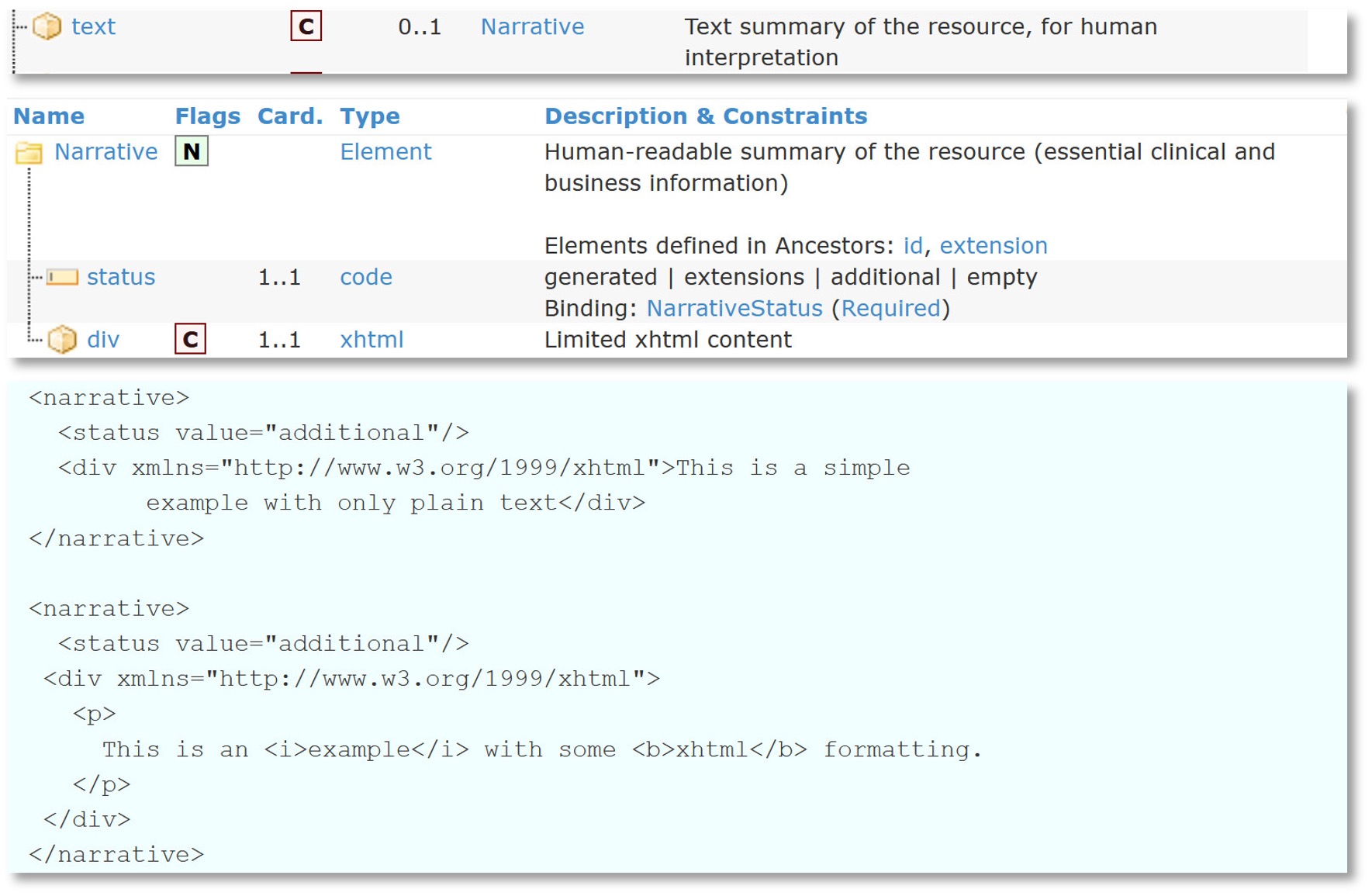
De tekst zal soms gebaseerd moeten worden op de inhoud van meerdere resources. Een tekstuele samenvatting van een recept zal meestal een goede omschrijving van de voorgeschreven medicatie moeten bevatten. In de tekst van een procedure wil je graag weten wie die procedure heeft uitgevoerd – niet alleen de naam van de arts, maar ook het specialisme van die arts en de organisatie voor wie deze arts werkt. In het algemeen dient de tekst zo opgesteld te worden dat zij niet specifiek voor één context relevant is, de resource kan immers ook in andere contexten gebruikt worden.
Implementatieaspecten
Systemen kunnen zelf besluiten hoe ze resources voorzien van een tekstuele samenvatting. Tekst dient te worden aangemaakt door het bronsysteem van een resource of een systeem dat zich in dezelfde context als het bronsysteem bevindt – die systemen hebben nog het meeste weet van de context, kennen de gebruikte profielen, de value sets en de gebruikte extensies. Het maken van een tekstuele samenvatting kan niet worden overgelaten aan een cliënt, die kan geen goede tekst genereren aangezien het niet alle gestructureerde data in een resource zal begrijpen.
Access control regels kunnen verhinderen dat een FHIR server de hele tekst mag opleveren, wat er toe leidt dat een server in feite tekst moet gaan genereren op het moment dat deze bevraagd wordt. Een nieuwe tekst zal eveneens gegenereerd moeten worden als er iets wijzigt in de resource.
Zorggegevens hebben lange (wettelijke) bewaartermijnen en om die reden zou de tekst zo opgemaakt moeten worden dat zij eenduidig wordt getoond ongeacht de browser en het type scherm waarop de tekst getoond wordt. Om die reden dient met zeer terughoudend om te gaan met opmaakmogelijkheden van HTML en CSS. De focus dient te liggen op de inhoud en niet op de opmaak daarvan.
- Als één of meer van de opmaaksopties worden gebruikt die in de FHIR standaard genoemd worden, dan betekent dat nog niet dat clients zich daaraan hoeven te houden.
- Gebruik tabellen uitsluitend indien de data een tabellarisch formaat heeft en niet als vormgevingsinstrument. Een zinsconstructie of een lijstje volstaat veelal als alternatief. Een tabel die bestaat uit 2 rijen of 2 kolommen, waarbij één daarvan de namen van data-elementen bevat is vrijwel altijd een teken dat er oneigenlijk een tabel wordt gebruikt.
- Systemen die tekst genereren, moeten er rekening mee houden dat een client moet werken met resources afkomstig van meerdere systemen, die elk hun eigen opmaak gebruiken om de tekst te structureren. Sommige tekst is wellicht al jaren geleden aangemaakt. Je zou een consistente vormgeving wensen voor alle teksten. Dit is niet haalbaar in de praktijk, een dergelijke consistentie valt niet te garanderen.
Het automatisch genereren van tekst is complex, zeker voor internationale softwareleveranciers, die te maken hebben met allerlei profielen, meerdere talen, en grammaticale verschillen in zinsconstructies. Diverse FHIR servers en tools bezitten configureerbare tekstgeneratoren voor FHIR resources die het genereren van tekst vergemakkelijken.
Concluderend
Het gebruik van tekst is noodzakelijk indien resources buiten hun originele context gebruikt worden. Je kunt niet van alle systemen in alle contexten verwachten dat zij de details van alle resource types uit (oude) FHIR releases correct kunnen verwerken, noch dat zij weet hebben van alle gebruikte FHIR profielen en extensies. Het genereren van tekst betekent meer werk voor de huidige systemen, maar op lange termijn verdient deze inspanning zich terug.
Op dit moment weegt het korte-termijn nadeel dat gepaard gaat met het genereren van tekst kennelijk zwaarder dan de lange-termijn voordelen van het aanwezig zijn van tekst in resources. Naar verwachting zal FHIR langdurig voor allerlei projecten ingezet gaan worden in Nederland. Daarmee is het aan ons, als gebruikers van FHIR, meer prioriteit te geven aan het gebruik van tekst in FHIR resources.
Tekst: René Spronk